Hadoop HDFS
《Hadoop 权威指南》读书笔记
HDFS是流式访问的:一次写入,多次读取且只支持单个写入者,而且是增量写入的
HDFS的几个基本概念
- 数据块:默认为128MB
💡 这个128MB与磁盘的传输速率是匹配的,如果传输速率提高,那么就可以有更大的 block 大小
- namenode 和 datanode
- namenode:维护文件系统命名空间(树):永久保存在本地磁盘
- datanode:储存并检索 blocks,定期向 namenode 报告储存的 block 列表
- 两种容错方法:备份文件或者添加辅助namenode
- 块缓存:一般一个块仅在一个datanode中有块缓存
- 联邦HDFS:在数据规模太大时,内存会成为瓶颈——允许多个namenode
- 高可用性
💡 区分高可用性和备份:高可用性需要在原有的down之后在不可被用户感知的时间内有新的主机上线
Hadoop2 维护高可用的方式
有一对namenodes处于主备配置。如果活动namenode故障,备用namenode将接管其职责,以继续为客户端请求提供服务而不会出现重大中断。需要进行一些体系结构更改才能实现这一点:
- namenodes必须使用高可用共享存储来共享编辑日志。当备用namenode启动时,它将读取共享编辑日志的末尾以将其状态与活动namenode同步,然后继续读取由活动namenode编写的新条目。
- 由于块映射存储在namenode的内存中而不是磁盘上,因此datanodes必须向两个namenodes发送块报告。
- 客户端必须配置以处理namenode故障转移,使用对用户透明的机制。
- 备用namenode的角色被主备namenodes代替,后者对活动namenode的名称空间进行定期检查点。
Hadoop 的高可用同时也是使用了 Zookeeper 的,在默认的情况下是用 Zookeeper+心跳监视来实现故障转移
接口
HTTP比原生的要慢,不要用他传输大文件(就是用 hdfs:// 这种访问来传输文件)
基于 Java 的读写
读:
1 | |
写:
1 | |
可以重载 Progressable 接口实现写入过程的 progress bar,也可以使用 append(Path f) 函数向一个文件的最后来追加
💡 create 函数可以创建不存在的父文件夹,尽管这样做可能有时并不安全,是递归创建的append 由于调用了 create,因此也拥有这样的特性
此外,用 FileSystem 的 mkdir 可以创建目录,尽管通常情况不需要这样做
文件系统
FileStatus 类保存了文件的 metadata,同时 FS 可以通过 listStatus 函数来列出目录中的所有内容
1 | |
globStatus 方法用于匹配通配符,复杂的基于正则表达式的匹配需要实现 PathFilter 接口
delete 来删除数据,并可以决定是否递归删除
读写流程解析
读流程
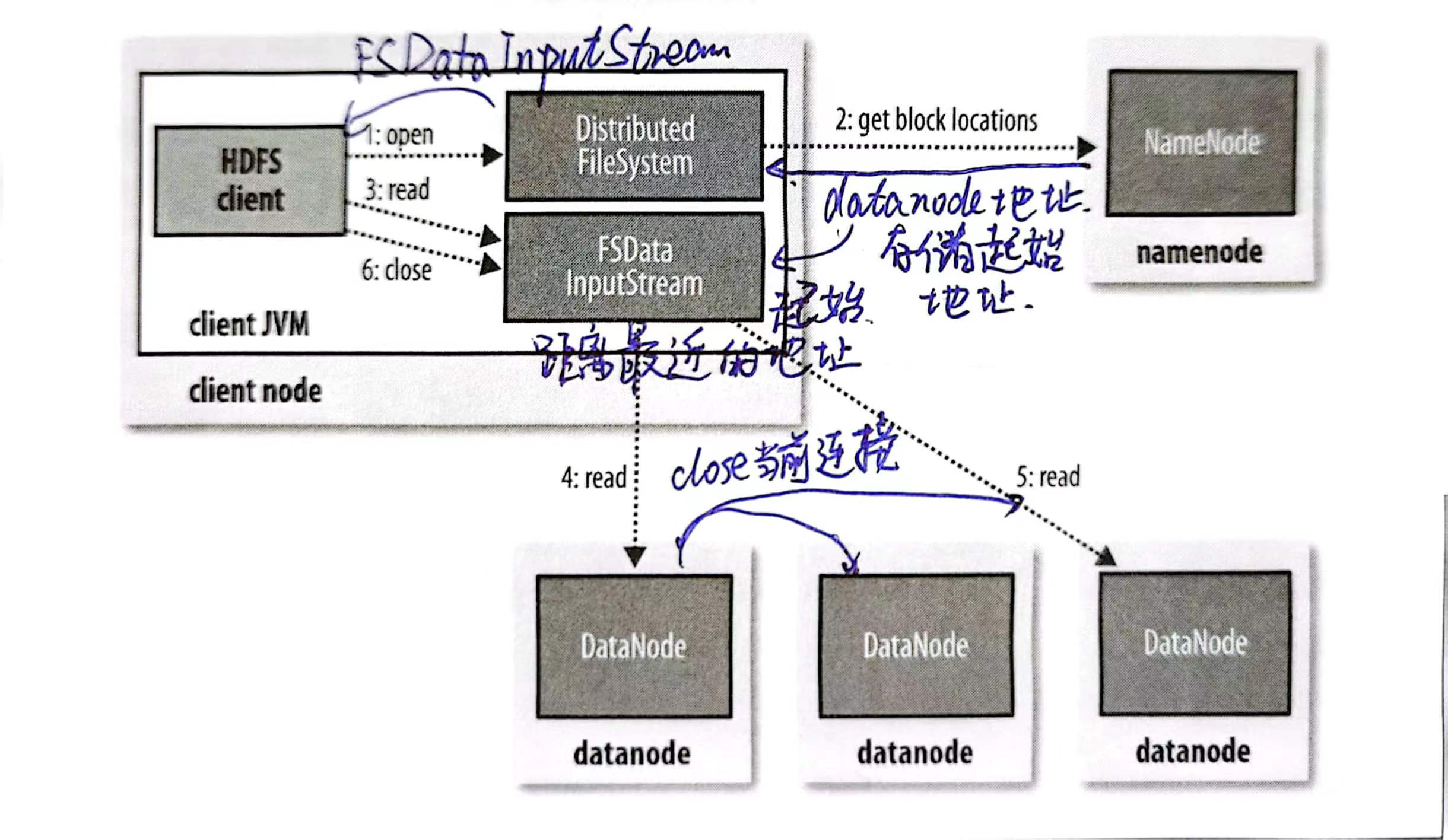
open打开一个要读取的文件,创建 InputStream- 这个过程通过 FileSystem 向 Namenode 发送一个RPC实现,申请文件起始块的地址
- 对于每一个块请求,Namenode 会返回一个 block 所在的 Datanode 的地址
- 这些地址是按照网络拓扑的远近顺序返回的
read函数让 InputStream 去进行读操作,InputStream 会找到最近的 Datanode 读取第一个块- 在这个块读取完时,InputStream关闭和这个 Datanode 的连接,并转到下一个最近的 Datanode 继续读取
- FS 向 Namenode 请求文件块的地址是一批一批的,在这一批读完前会请求到下一批的地址,读取过程是连续的
- Namenode 储存文件快的起始地址是在内存中的,所以非常高效
- 读取完成后关闭连接
🔴 容错和故障处理:如果发现连接失败或者读取的块不完整,FS 会通知 namenode,以后不从这个 datanode 中进行读取。
写流程
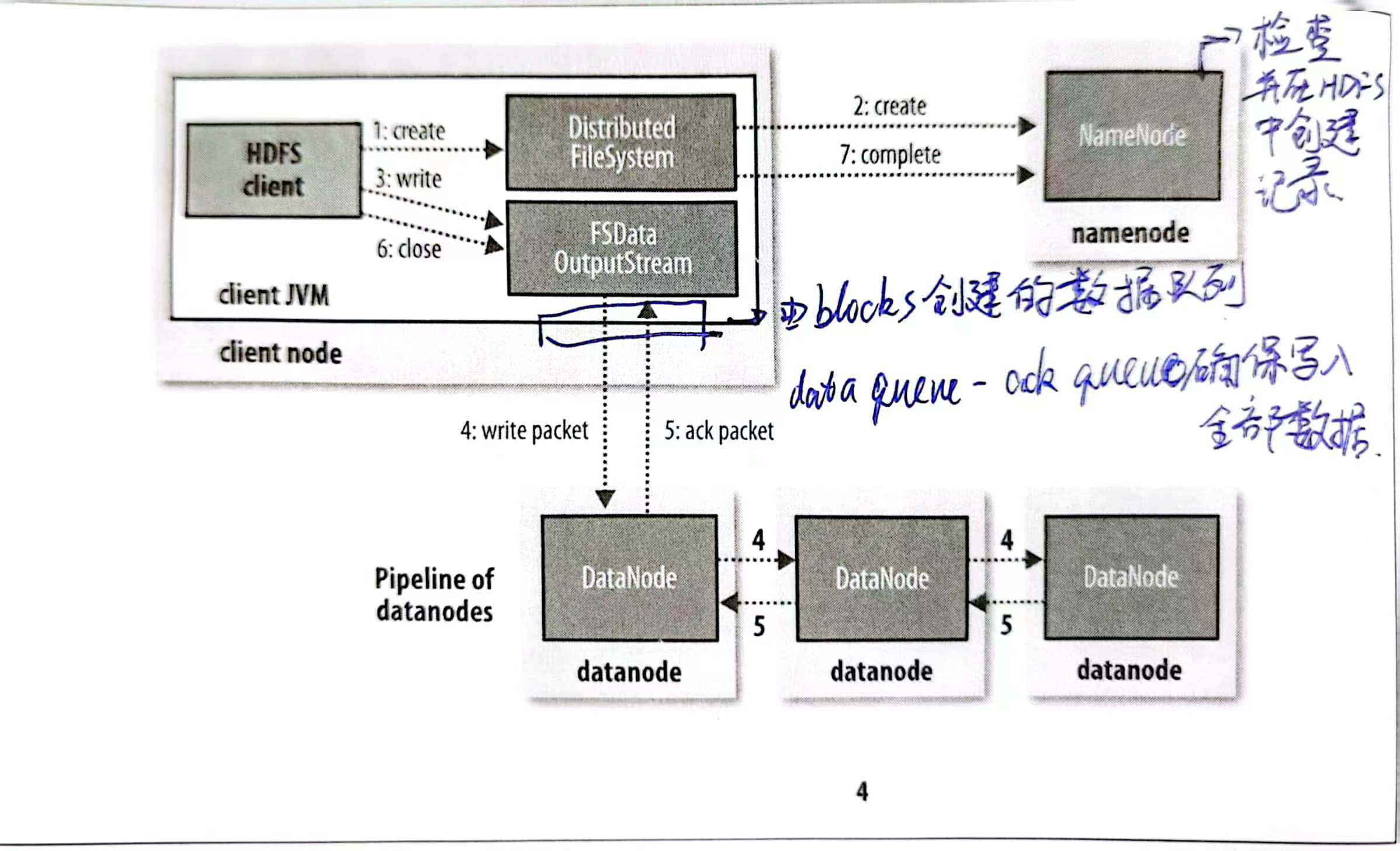
- 首先用
create方法来创建文件,然后同样由 FS 向 Namenode 发送一个 RPC 来进行 namenode 处文件记录的创建 - Namenode 会进行也系列检查确保创建是合法且有权限的,然后返回给 FS,这个时候 FS 会返回给 client 一个 OutputStream。OutputStream 负责进行 Namenode 和 datanode 的通信。
- OutputStream 将要写入的 blocks 放入一个 data queue,然后执行一个流水线过程
- OutStream 将 block 写入请求到的最近的 datanode
- 然后datanode将其流水线写到 replica 的 datanode中
- 然后再流水线返回
- OutputStream 还维护一个 ack queue,记录完全写完的block
🔴 故障容错处理:如果有一个写入故障的数据包,立刻关掉整个pipeline,把所有在pipeline 中的数据包返回到数据队列的前端,然后在正常的 datanode 的 block 制定一个表示,然后传递给 namenode。 namenode 意识到 repica 不足时,会继续在新节点上创建副本
- 整个在写入完成后调用 close 方法
distcp复制
distcp 可以提供 HDFS 之间的大批量复制