HDFS I/O
数据完整性
HDFS 通过校验和的计算来保证完整性,一般认为计算4个字节的校验和带来的额外的存储(1%)和计算开销都是可接受的
HDFS 在以下几个层面保障数据完整性:
- datanode 在收到数据后验证 checksum,在整个写过程的 pipeline 的最后一个 datanode 负责校验和,返回 IOException
- 读取时也会校验 checksum,datanode 会维护一个 checksum 的检测日志,每一次读取检查后更新检测日志
- datanode 的后台线程也会定期检查存储在 datanode 中的所有块的 checksum
处理损坏块的方法是直接覆盖或者把当前这个datanode中的块放弃掉,尝试将数据复制到新的datanode
在本地系统可以使用 LocalFileSystem 实现数据完整性的检验,同时可以用 ChecksumFileSystem 进行其他文件系统的封装
压缩
集中常见压缩的优缺点:
- gzip:DEFLATE算法,无法切分,压缩解压缩速度比较快,适合中途小文件的传输(map过程中)
- bzip2:可以切分,用于创建map任务,但是压缩解压速度慢
- lzo:在构建索引的情况下可切分
- snappy:不可切分,也是快速压缩算法
Hadoop 对于集中常用的压缩算法都有对应的 Codec 类进行实现
压缩的编程实现
使用 codec 实现:
1 | |
上文的通过反射的实例构建也可以通过一个工厂类来实现 CompressionCodecFactory.getCodec() ,通过文件的后缀名来推断压缩类型
💡 在压缩解压的过程中直接调用原生(native)代码库可以显著提升速度
在需要执行大量压缩解压缩的过程时也可以使用 CodecPool
MapReduce 中的压缩
💡 压缩格式的选择:尽量选择可切分的压缩格式,或者在压缩前进行切分,然后分别压缩,保证切分的结果近似地等于HDFS块的大小
通过以下方法在 job 的 output 中直接集成压缩:
1 | |
同时可以通过 config 来设置是否在 map 的中间结果中使用压缩,以获取进一步的性能提升
序列化
序列化用于分布式数据处理的两大另一:进程间通信和永久存储
序列化需要的特点:紧凑(节省带宽),快速(复用次数高)、可拓展(总会有新的需求)、支持互操作(不同端的交互)
Writable
Hadoop的序列化通过 Writable 接口实现,然后 Writable 接口有衍生出来分别对应了不同的 java 数据类型的 Writable 类
1 | |
其中 DataOutput 和 DataInput 是 java.io 中的两个接口,其实现分别是 DataOutputStream 和 DataInputStream
WritableComparable 由其名字可以看出,分别实现了Writable 和 Comparable 这两个接口,对应的 WritableComparator 则稍有不同,这个类在具体实现的同时,还充当了一个工厂类的角色,生成不同类型的 RawComparator
1 | |
下面可以去看一下
WritableComparator这个类的源码,因为后面对于TextPair的comparator的构建要用到这个类下面是一个Hadoop Writable 的继承关系图:值得注意的是 int 和 long 对应的 Writable 有变长版本,一般会使用变长版本的,这样比较节省空间
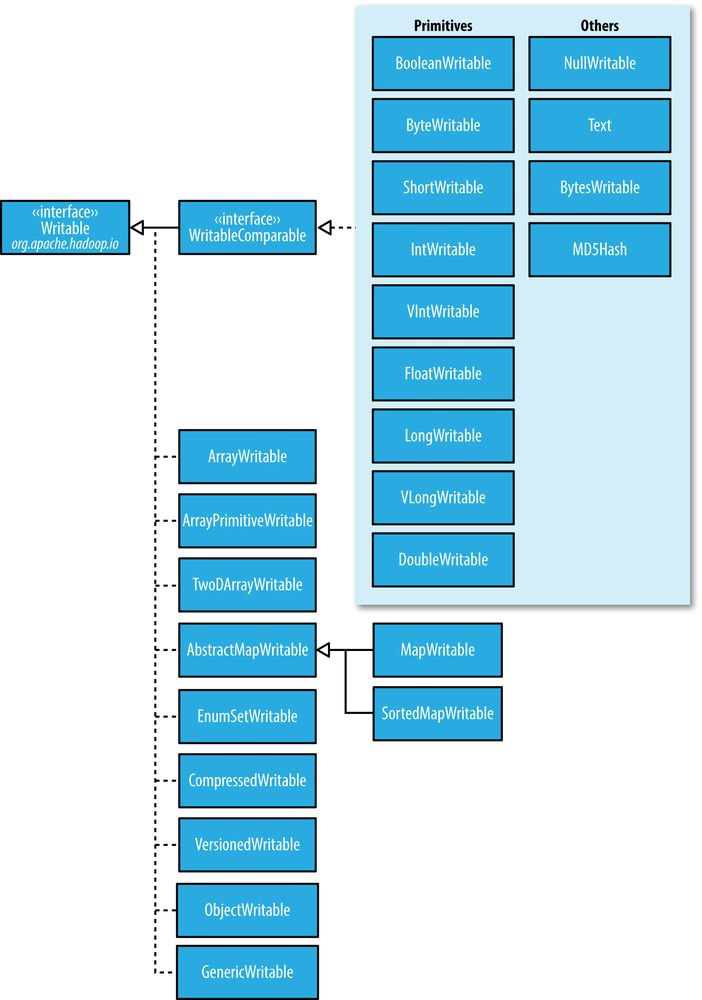
Text 类型相当于 String 但是在索引上又有所不同,Text 的长度是按照 Byte 进行计算的,索引(charAt())也大多会索引到 byte。Text 的这种特性也使得其遍历相当麻烦,需要用如下一个利用 ByteBuffer 进行转换的方法遍历每一个字符,当然直接调用 toString() 方法可能是更方便的操作。
1 | |
❓ 那什么时候只能对 Text 进行操作呢,一行特别长吗?但是这样的情况在读取的时候不会有处理吗,比如一个块其实也就128M,这128M也不会一次直接全读成 Text
NullWritable 在 MapReduce 过程中不需要某一个 value 时可以声明,可以高效存储空值,节省带宽
❓ 一个不太重要的小问题:ObjectWritable 和 GenericWritable 的区别? 书上给出的事 GenericWritable 使用静态类型的数组并加入索引以提高性能。
Writable 的定制化
如果我们希望针对一个 Hadoop 没有实现的数据结构实现在 Hadoop 上的序列化,我们最好的方法是新建一个新的 Writable 类型
在新建 Writable 类型后,我们往往为了避免在比较过程中需要将对象进行反序列化,需要重新写一个 RawComparator 想办法在字节层面上对对象进行比较
Serialization 是一个比 Writable 更大的范畴,Hadoop 也提供了一个除了包含 Writable 的更 general 的 framework,除此之外还可以使用别的,比如 Avro
SequenceFile
SequenceFile 设计出来有两个功能:
- 一方面可以提供一个二进制的键值对存储结构
- 另外一方面可以作为小文件的容器对小文件进行包装(why?)
💡 通常解决”小文件问题”的回应是:使用 SequenceFile。这种方法的思路是,使用文件名作为 key, 文件内容作为 value
在实践中这种方式非常有效。我们回到10,000个100KB大小的小文件问题上,你可以编写一个程序 将合并为一个 SequenceFile,然后你可以以流式方式处理(直接处理或使用 MapReduce) SequenceFile。这样会带来两个优势:
SequenceFiles 是可拆分的,因此 MapReduce 可以将它们分成块,分别对每个块进行操作;
与 HAR 不同,它们支持压缩。在大多数情况下,块压缩是最好的选择,因为它直接对几个记录组 成的块进行压缩,而不是对每一个记录进行压缩。
将现有数据转换为 SequenceFile 可能会很慢。但是,完全可以并行创建一个一个的 SequenceFile 文件。 Stuart Sierra 写了一篇关于将 tar 文件转换为 SequenceFile 的文章,像这样的工具是非常 有用的,我们应该多看看。向前看,最好设计好数据管道,如果可能的话,将源数据直接写入 SequenceFile ,而不是作为中间步骤写入小文件。
与 HAR 文件不同,没有办法列出 SequenceFile 中的所有键,所以不能读取整个文件。 Map File, 类似于对键进行排序的 SequenceFile,维护部分索引,所以他们也不能列出所有的键
原文链接:https://blog.csdn.net/qq_43061290/article/details/124822293
读写操作
读
reader可以直接实例化,然后通过 next() 和 getCurrentValue() 来读取
1 | |
❓ 这里有一个问题,我们可以发现代码中提供的读取方式和书中提供的API 是有一些差别的
还可以通过 seek(int pos) 函数在顺序文件中进行搜索,但是这个 pos 如果不是边界值的话会报错
也可以用 sync(int pos) 方法来寻找下一个同步点,这个同步点是由 Writer 在写的过程中创建的
💡 同步点提供在读取过程中因为搜索导致文件指针 lost 后可以快速同步
写
通过一个可以操作多种数据类型的 createWriter() 创建一个 writer,然后用 append() 函数向其中添加 key 和 value 即可,同时 writer 也是一个 Closable 流,需要 close
1 | |
writer 中 key value 的类不一定是 Writable ,但是至少应该可以被序列化
💡 SequenceFile 可以很方便用 mapreduce 进行排序合并,或许为管理小文件提供了一些帮助?
结构
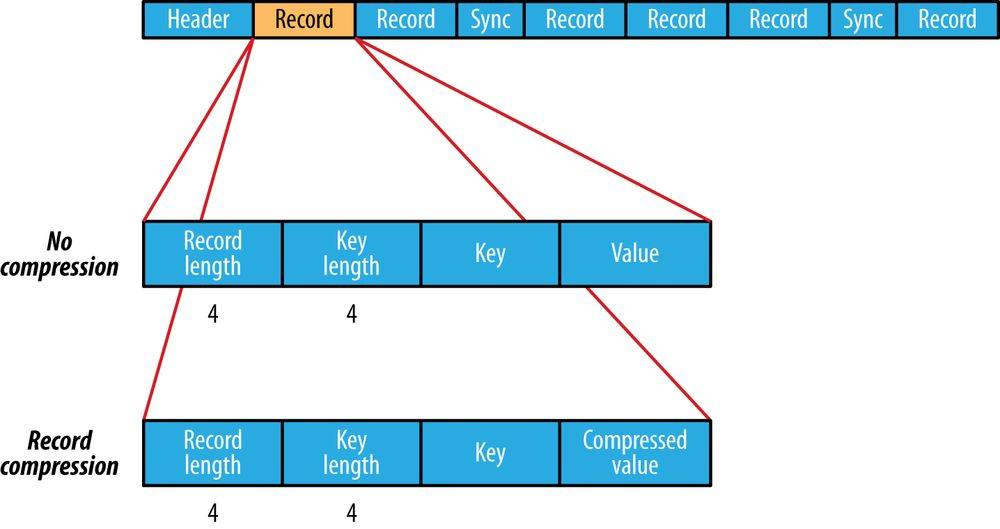
Record Compression (Default)
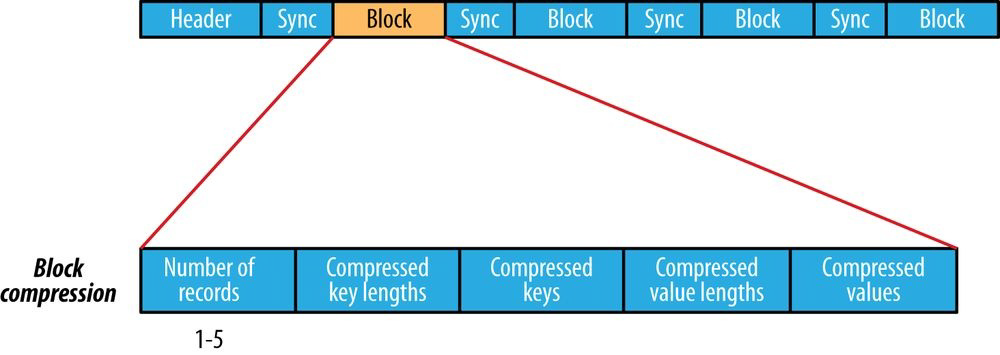
Block Compression
❓ 另外一个不太重要的问题,怎么从压缩的里面读取一条记录
块压缩是用记录中的相似性进行压缩的