Zookeeper简介
Zookeeper 可以用来构建一般的分布式应用,对部分失败进行正确的处理
💡 什么是部分失败?简单来讲就是消息在网络中传输的一方不知道另一方是不是有问题,比如接受者down掉或者根本没有接受到,发送方是不能知道这条个操作是不是已经失败的
Zookeeper 的一些核心理念:
- 精简的文件系统
- 高可用性:避免出现单点故障,构建可靠应用
- 松耦合:让进程在不了解其他进程(或网络状况)的情况下能够彼此发现并实现交互,甚至不要求二者是同时存在的
- 高性能:10000ops +
Zookeeper 的一些命令行指令:基本都是4个单词的,通常在 port:2181 进行监视
Zookeeper 服务
数据模型
Zookeeper 被设计用来实现协调服务,其数据的访问具有原子性
💡 也就是说与 HDFS 不同,其读取数据时不会出现部分读,要么成功,要么失败,同样的,对于写操作来说,其也会一次性更新 znode 中的所有数据,而不是只在最后进行添加。
Zookeeper保证了读写的原子性
znode
znode 分为短暂 znode 和永久 znode。其中永久 znode 需要显式地被删除,而短暂 znode 在当前客户端的会话结束时就会消失
💡 关于会话(session)和连接(connect)之间的区别,请看后文的内容
短暂 znode 不可以用有子节点,其比较适合实现组成员管理,让进程知道特定的时刻有那些子成员可以被使用。
💡 详情见 21.2.3, 21.2.4 中 JoinNode 和 ListNode 的例子,短暂 znode 添加的子成员能够被 ListNode 在他们不知情的情况下发现。
Sequence Number
顺序号可以给全局的同名时间排列顺序,比如两个先后有不同客户端创建的 znode 在 Zookeeper 路径中会被管理为 /a/b-2 和 /a/b-3 。顺序号并不会在路径访问中被显式需要。
💡 顺序号涉及到了 Zookeeper 另外一个非常重要的功能,就是实现分布式锁
Watch
每一个 znode 都可以设置多个观察,有不同的对于 znode 的操作可以触发观察。观察在触发后会通知设置该观察的客户端,然后消失。
💡 也就是说每一个观察只能触发一次,如果想要多次接受通知,需要不断的设置观察
操作

在更新( setData , delete 时需要提供版本号,可以由 exists 方法获取,且这个更新操作是非阻塞的(可能同时由其他的客户端在更新)
Zookeeper 提供了一个 multi 的操作,可以将多个操作打包为一个原子性的操作,一起成功一起失败
Zookeeper 提供了同步和异步的API,通常会使用异步的API以流水线的方式来处理请求。
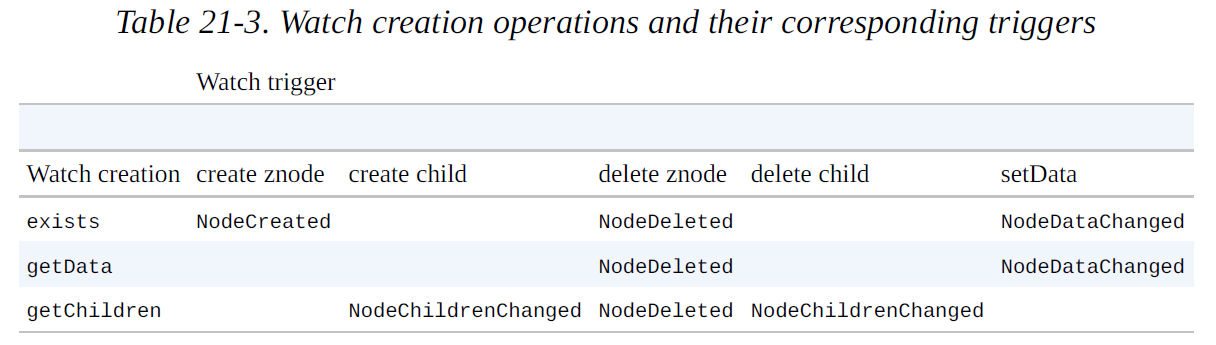
这个表提供了什么操作的可以对 znode 设置观察,以及他们是怎么被出发的
Zookeeper 还提供了权限管理的功能,用户登录需要通过身份验证(IP,或者密码组合等方式)来获取自己的 ACL (Access Control List)
实现
有两种模式:standalone(单机)、replicated
在复制模式先,需要集群中有超过一半的机器可用,所以一般 Zookeeper 集群中总是有单数台机器(比如5台-容忍2台宕机,但是 6台服务器同样只能容忍2台宕机)
一般有两个阶段
- 领导者选举:选出一台保持最新状态的 leader,其他人成为 follower
- 原子广播:所有对于 znode 的更改都会现在 leader 中更改并持久化,然后 leader 才回广播这个修改,而且这个达成协议的过程对于每一个节点都是原子性的。
- 一旦领导者出现问题,会快速再选选举一个领导者,然后恢复正常的原 leader 会自动不变为 follower
一致性
一个 follower 可能落后 leader 数个版本,可以通过 sync() 函数完成一致性更新。
每个 Client 并不知道自己连接到的是 follower 还是 leader,但是只有他重新连接,他就不会连接到比自己原先更老的服务器版本,这一点有 znode 顺序号进行保证。
顺序一致性、操作原子性、更新持久性等均可以实现对于 Zookeeper 的一致性保证
会话
客户端一旦与一个 Zookeeper 服务器建立连接就产生了一个 Session,客户端可以定期发送 ping 信号来保证 session 不过期
💡 session 连接的 Zookeeper 服务器故障后,Zookeeper 保证了对于服务器的自动切换,所有与故障服务器相关的 session 在切换后仍然是有效的,这个切换过程对于用户是透明的
ping 的时间通常会设置为 2~20 个 tick,tick一般为 2s
通常来说,服务器越多,构建的暂时状态越复杂,越应该设置较长的 ping 时间
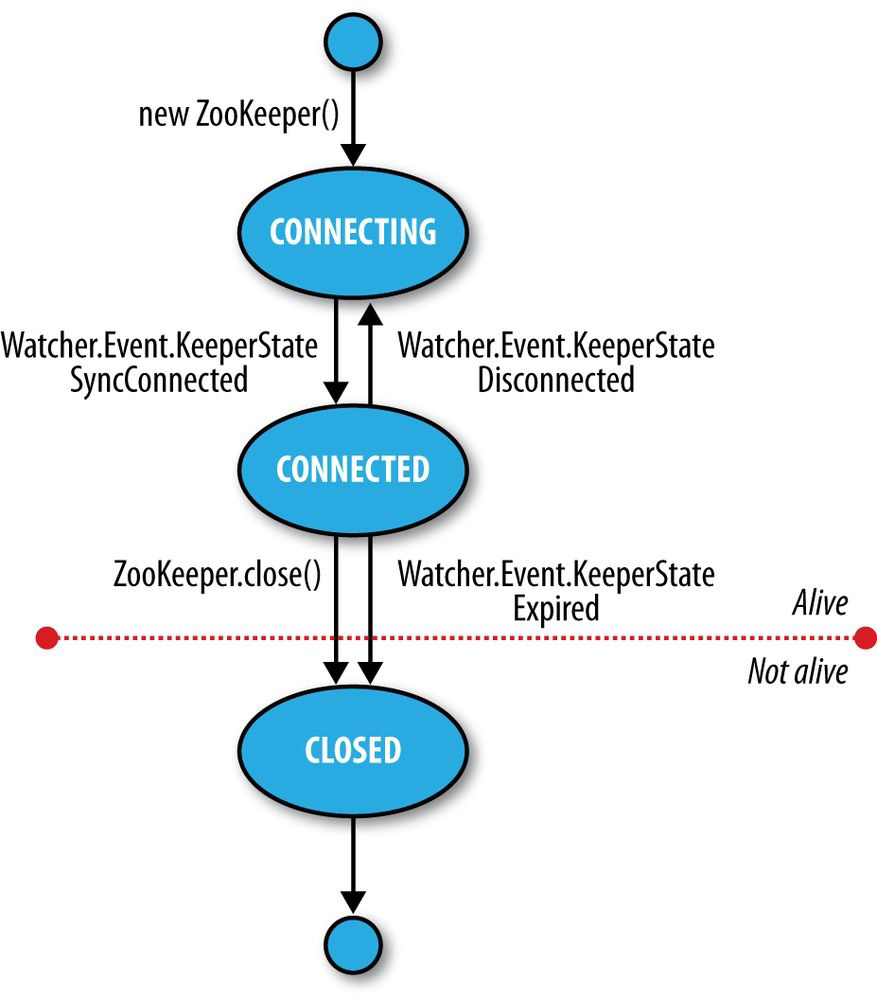
状态
状态图如下,一个 Zookeeper 对象只能出于一种状态,同时状态的切换会出发 watcher
Zookeeper 构建应用
配置服务
Zookeeper 可以作为一个高可用的配置存储器,允许分布式应用的参与者检索和更新配置文件
可以利用 znode 以键值对的方式存储配置,并提供多种层级的支持
利用 Watcher 观察 NodeDataChanged 事件来在不同的客户端中同步配置
可复原的 Zookeeper 应用
捕捉 KeeperException ,并根据其类别来对应用进行恢复
要注意幂等和非幂等操作的区别,幂等操作可以多次重复,而非幂等操作啧不能盲目的重试
分布式锁
提供一组进程间的互斥机制,可以用于在大型分布式系统中实现领导者选举,持有锁的进程就是领导者
思路很简单,创建一个锁的 znode,然后在他的下面创建一些子 znode,如 /leader/lock-1, /leader/lock-2, 任何时候顺序小的持有锁
申请获取锁的伪代码:
1 | |
两个潜在的问题:
羊群效应
- 解释:每个 client 都会在锁 znode 上放置一个观察,每次状态变化时会可能会有大量的客户端受到同一事件的通知,但是只有很少一部分需要处理这个事件,这样会造成网络带宽的峰值压力过大
- 解决:只在当前子节点消失时,通知其下一个子节点
可恢复异常
- 描述:在创建锁 znode 时,我们不能处理由于连接丢失导致的创建失败(partial failure)。我们不能简单的进行重试,否则会出现孤儿 znode
- 解决:在znode中加入 sessionID,构成
lock-<sessionID>-<sequenceNumber>的名称序列,在重新连接时进行搜索。
生产环境
还会存在除了 leader 和 follower 之外的角色:observer,是没有投票权的跟随者,可以将 observer 放置在不同于 leader 和 follower 的机架中,这样既不影响性能,也能够提高整个 Zookeeper 服务的可用性
主要使用 3 个端口:
- 2181:客户端连接
- 2888:对于 leader 来说,follower 从这个端口进行连接
- 3888:领导者选举阶段的其他服务器连接
应用:
- 为 HDFS 的 Namenode 提供高可用性支持
- 为 Yarn 的 resourcemanager 提供高可用支持
主要是快速的主备切换